The Problem:
Ever find yourself working with a large-ish SVN repository that includes many sub-projects, and you only want to work on a subset of those sub-projects, but you don't want to deal with all the extra cruft involved in checking out at the top level of the repository?
"What's this guy talking about?"
Sorry, a picture will help me explain. Below is a snapshot of an old repository of one of products we develop here at work:
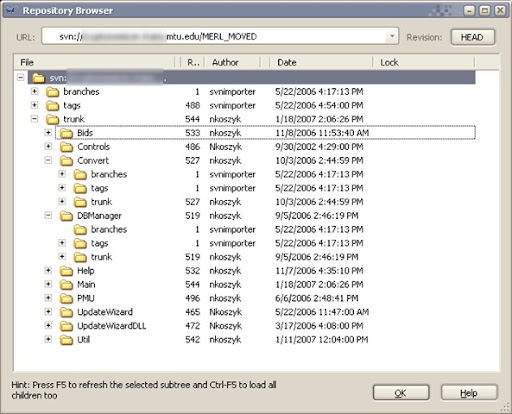
As you can see, trunk consists of multiple sub-components, each of which have their own branches/tags/trunk folders. Whether or not this is the best repository layout could be up for debate, but it seems to treat us well with the design of this project. (We have a repository layout similar to this for another project we have, and it seems to serve us well there as well.)
The big problem we have with this repository layout is that you never want to checkout that top-level trunk. You end up with all of the sub-branches and tags folders that are not only superfluous, but also waste space and make the commit or update process so much slower because SVN must check all the sub-folders for modifications.
What ends up happening, for example, is someone needs to work on the "Bids" and "Main" components at the same time. To facilitate this without checking out at the trunk-level is they create two separate working folders, and check out each respective component's trunk (or appropriate branch). When they commit, they have to make two separate commits.
While this works, it's not desirable, especially if you aspire to reach Continuous Integration nirvana. Not being able to create an atomic commit across various working folders could potentially break things in a CI environment if changes in one component rely upon the changes of another. Even if CI isn't your eventual goal, an atomic commit of 'grouped changes' just makes sense.
"What to do?"
The Fix:
Well, the good news is that Subversion 1.5 is supposed to have better support for 'partial checkouts'. I'll admit I haven't kept up with that aspect of v1.5, to be totally honest, I'm more excited about merge tracking. But that's for another post.
But anyway, there is a work-around in SVN 1.4.x (and probably earlier versions..sorry for not doing any fact-checking here.) Well, maybe work-around isn't the right word, it's more of an off-label use of a repository feature.
Before continuing on, you must know that I'm primarily a Windows developer. I use Subversion on Windows via the excellent TortoiseSVN front end. The following how-to is going to be using TortoiseSVN. Everything that follows is entirely possible with the command line SVN tools, and, if there's enough request, I'll update this post with how to do it from the command line. (email me!)
"Get to it already, would ya?"
Sorry, here we go, in short:
- Create a repository on your local machine.
- Checkout a working copy of the repository and specify an svn:external property that will link to the portions of the remote repository you really want to work with. (Read the SVN Book for important notes and details.)
- Commit this svn:externals property back to the local repository.
- Update you working copy of the local repository and you'll have checked out the parts of the remote repository you want to work with.
Details:
Create a new folder somewhere on your machine, make sure it's in a place that you won't forget, and in non-obtrusive location because once this is created, it can't be moved without causing you pain in the process. ;)

MyFilterRepo is a folder on my desktop. Now, using TortoiseSVN, create an empty repository inside that new folder. Right click on the folder, choose TortoiseSVN -> Create repository here... Choose the 'FSFS' file system type.
Then, browse this repository, right-click the folder, TortoiseSVN->Repo-browser:
Create a 'trunk' folder (or any other folder...it doesn't really matter:)
Create another empty folder some place. Checkout the trunk folder from the repository you just created by specifying the file:///bla/bla/bla/trunk style URL:
Now, specify the svn:external properties that will link your local repository's trunk folder to multiple remote repository folders. To do this, right-click on your working folder, and choose TortoiseSVN->Properties. In the dialog that pops up, click the 'Add' button. This will bring you to this dialog:
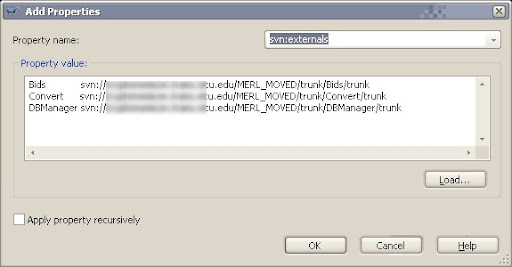
Choose 'svn:externals' From the Property name combo box. In the Property value text box, you will need to enter key/value pairs of the remote repositories. The first item on the line is what you want folder to be named in your local repository. The second item on the line is the full path to the remote repository. (If you have credentials already cached for the remote repository, you shouldn't have a problem, otherwise you'll probably be asked to specify your username/password when you update later.)
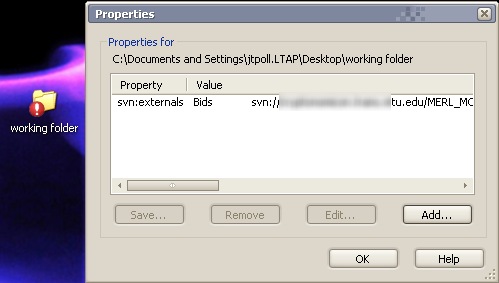
When you hit the "OK" button, you'll notice that your working folder has been changed:
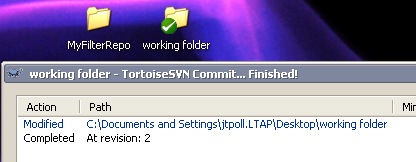
Now, commit your working folder back to your local repository. Don't worry, the repository(ies) linked via the svn:externals property will not be modified at this time.
Now, update your working folder. You'll notice that all of the repository locations mentioned in your svn:externals property will be checked out to your working folder. Hooray! You did it!
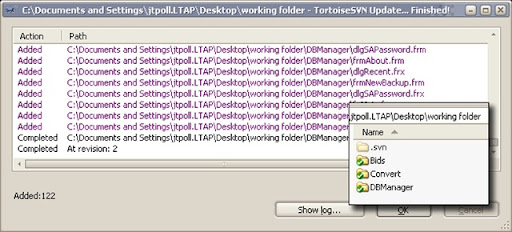
You are now able to work in the sections of the remote repository that you want to work on, while completely ignoring all the other cruft that you don't want to see or care about. When you commit any changes to this local repository, you'll be pushing those changes to the remote repository in a single atomic commit.
(I must admit, I originally found this via tortoisesvn.net, but since it's been one of those issues that I've dealt with for so long, I decided I had to duplicated the work-around here. )
To further understand how this works, I must again point you to the section of the official SVN book that describes externals, and what they're really intended to be used for.
Let me know if this helps!
Update - Gotchas
Surprisingly, there are very few gotchas with this technique. Thankfully, the only ones I've discovered are easily worked-around.
So, you have multiple externals defined, and you've made changes to the various external 'parts', like so:
Normally, to commit those changes, you'd go to the parent folder, and choose to commit from there. The problem is, as you'll notice, is that TortoiseSVN will give you a message like:
You'll also notice that the list of modified files doesn't include your changes. Notice how the message states that you'll have to commit those changes separately. If we'd RTFM'd like we were supposed to, we'd notice the paragraph near the bottom of Chapter 7, Section 3 of the SVN Book states: "So, for example, if you want to commit changes that you've made in one or more of those external working copies, you must run svn commit explicitly on those working copies—committing on the primary working copy will not recurse into any external ones."
This is exactly what we're trying to not do! Thankfully, there's a work-around which allows us to still create atomic commits across those externals:
- Go into the the working folder
- Select each folder that has modifications that you want to commit.
- Right-click -> SVN Commit
- TADA
Now, what we haven't ran into, but I imagine could theoretically happen is, what if one of those externally-included sources itself has external-definitions? For example, in the sample repository we've been using here, what if the DBManager had an external definition? If you made modification inside that nested external definition, there would be no way for you to commit the changes inside that nested external definition, and the changes in your home-spun externals repository.














